

How to build a functioning Knowledge Base?
The Knowledge Base is a living and changing place. It is never really finished, as the knowledge to be documented is virtually endless. It evolves over time, so we need to consider feedback from users, statistics on usage and changes in technology and processes. But let’s see the basics you should follow to successfully build a first version of your Knowledge Base.
Step 1 – The Foundation
We should start by gathering actual data from our Incident and Service Request tickets. The categorizations, to be precise. Sure, this only works if we have implemented some common categories before and if we have reporting capabilities. I assume that this should not be an issue because every ticketing system has predefined ticket categories and pre-built reports.
Step 2 – The End User
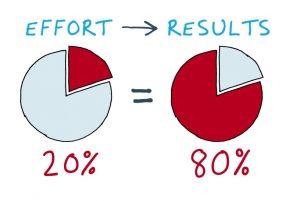
Our aim is to find out what the most common issues / service requests are that are raised by our end users. Once we got this, we should apply the Pareto Principle, meaning we should concentrate on the top 20% most common cases instead of creating knowledge articles for everything, because the 20% would cover around 80% of all calls to the Service Desk. You know…less is more in this case.
These user-centered knowledge articles need to be written in a user-friendly language and manner, as otherwise they would not be utilized and all the effort was for nothing. It might even make sense to test the articles with some end users.
Once articles are ready, they should be released into the part of the Knowledge Base, which is available to the end users, ideally through the self-service portal on the company intranet. The publication should happen incrementally, as it usually does not make any sense to wait for a number of articles to be completed before they are release. We are following the ITIL 4 Guiding Principles “Start where you are” and “Progress iteratively with feedback” 🙂
Step 3 – The IT users
Another part of the knowledge base is available to the IT users. This includes mostly the Service Desk but also any other IT function that is depending on the knowledge of others. To increase the resolution rate of individual groups, we should ask the knowledge holders (which are often more senior or expert teams) to create knowledge articles for the most common cases they receive. And again, the Pareto Principle should be applied.
Often senior teams can be very reluctant. “We don’t have time for that” or “What does it bring us?” are common things we might hear. But we can remind them, that the more stuff is resolved by the Service Desk or less senior groups, the more time our experts will have for other activities like development or projects.
The ultimate goal is to increase the First Call Resolution rate on the Service Desk as much as possible in an economical manner.
Step 4 – The Knowledge Centered Support (KCS)
KCS is a methodology, which centers the delivery of services and products around the knowledge needed for it. It tells us that documentation should be a by-product of handling cases and solving issues, but it also makes sure that the knowledge is relevant. That is done by ensuring that documentation is “living”, meaning that it is based on demand and usage. So, in other words, only knowledge articles that are really used should be kept “alive” and updated. The rest shall be removed, as keeping those updated is only overhead work.
During my time on the Service Desk, we used an internally developed knowledge base, which had an integration to our ticketing system. In the tickets we created, we had a specific field for the knowledge article ID. If we entered an ID, it would prefill the ticket with some text. If we did not find any relevant article, we entered “00000” as the ID. Later the knowledge admins would pull a report on the article usage. The least used articles were removed every now-and-then and new articles were created if there have been some issues about the same topic where the tickets were marked with “00000”.
Knowledge Management is a neglected practice that can bring a tremendous value in form of customer satisfaction, green SLAs and happier IT staff when applied right.
Concentrating on the creation of knowledge articles for the most common issues and inquiries helps the users and IT stuff tremendously by reducing unnecessary workload.
Some effort needs to but put into grooming our Knowledge Base, but a good starting point is to analyze usage data and remove or adjust articles that are not used often or are downvoted.







-

ITIL® (version 5) Foundation Mock Exam Pack – 160 Practice Questions
Original price was: € 14,99.€ 9,99Current price is: € 9,99.













